

An Autonomous Planning Method for Deep Space Exploration Tasks in Reinforcement Learning Based on Dynamic Rewards
-
摘要:针对深空探测器的自主任务规划的多约束需求,提出了基于动态奖励的强化学习深空探测器任务自主规划模型构建方法,建立了深空探测器智能体的交互环境,构建了策略网络和融合资源约束、时间约束以及时序约束的损失函数,并提出动态奖励机制对传统策略梯度学习方法进行了改进。仿真实验结果表明,本文方法可以实现自主任务规划,规划成功率和规划效率相比静态奖励策略梯度算法有明显的提升,并且该方法能在任意状态下开始规划而无需改变模型结构,提高了对不确定规划任务的适应性。该方法为深空探测器自主任务规划与决策提供了一种新的解决方案。Abstract:Aiming at the characteristics of multi-system parallelism and the need to meet various constraints in the process of autonomous mission planning of deep space detectors, this paper proposes a reinforcement learning task autonomous planning model construction method for deep space detectors based on dynamic rewards, and establishes a deep space detector agent. In the interactive environment, a policy network and a loss function integrating resource constraints, time constraints and timing constraints are constructed, and a dynamic reward mechanism is proposed to improve the traditional policy gradient learning method. The simulation results show that the method in this paper can realize autonomous task planning. Compared with the static reward policy gradient algorithm, the planning success rate and planning efficiency are significantly improved, and the method can start planning in any state without changing the model structure, which improves the accuracy of the algorithm. Determine suitability for planning tasks. This method provides a new solution for autonomous mission planning and decision-making of deep space probes.Highlights
● An reinforcement learning interactive environment for deep space probe agents is built. ● The traditional policy gradient reinforcement learning method is improved by constructing a loss function which integrates resource, time and timing constraints for the task planning of deep space detectors. ● A dynamic reward mechanism is proposed. ● A deep space exploration task planning model with random initial state is presented. -

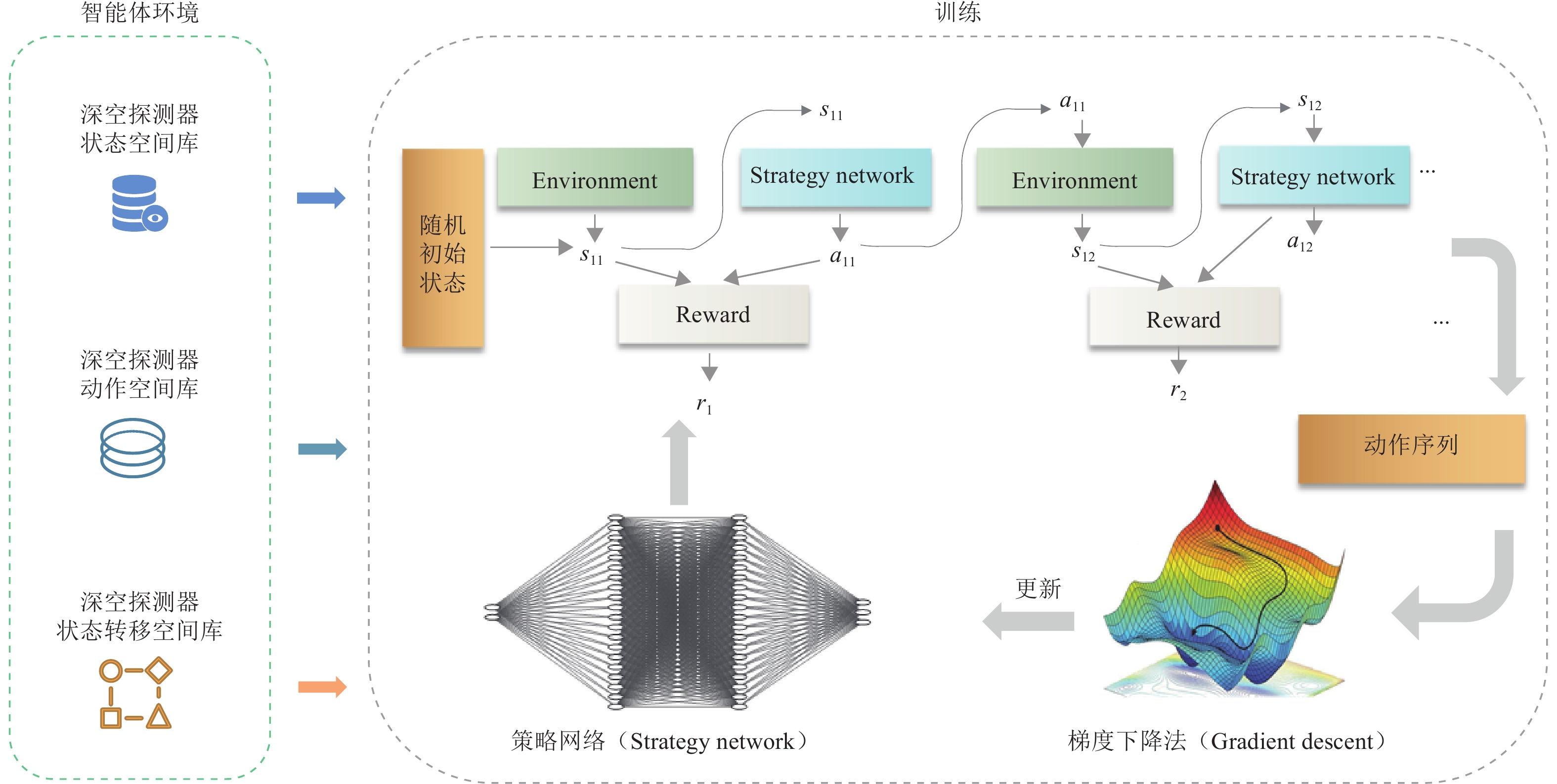
图 1基于策略梯度强化学习深空探测器任务规划方法原理图
Fig. 1Schematic diagram of the task planning method for deep space detectors based on policy gradient reinforcement learning

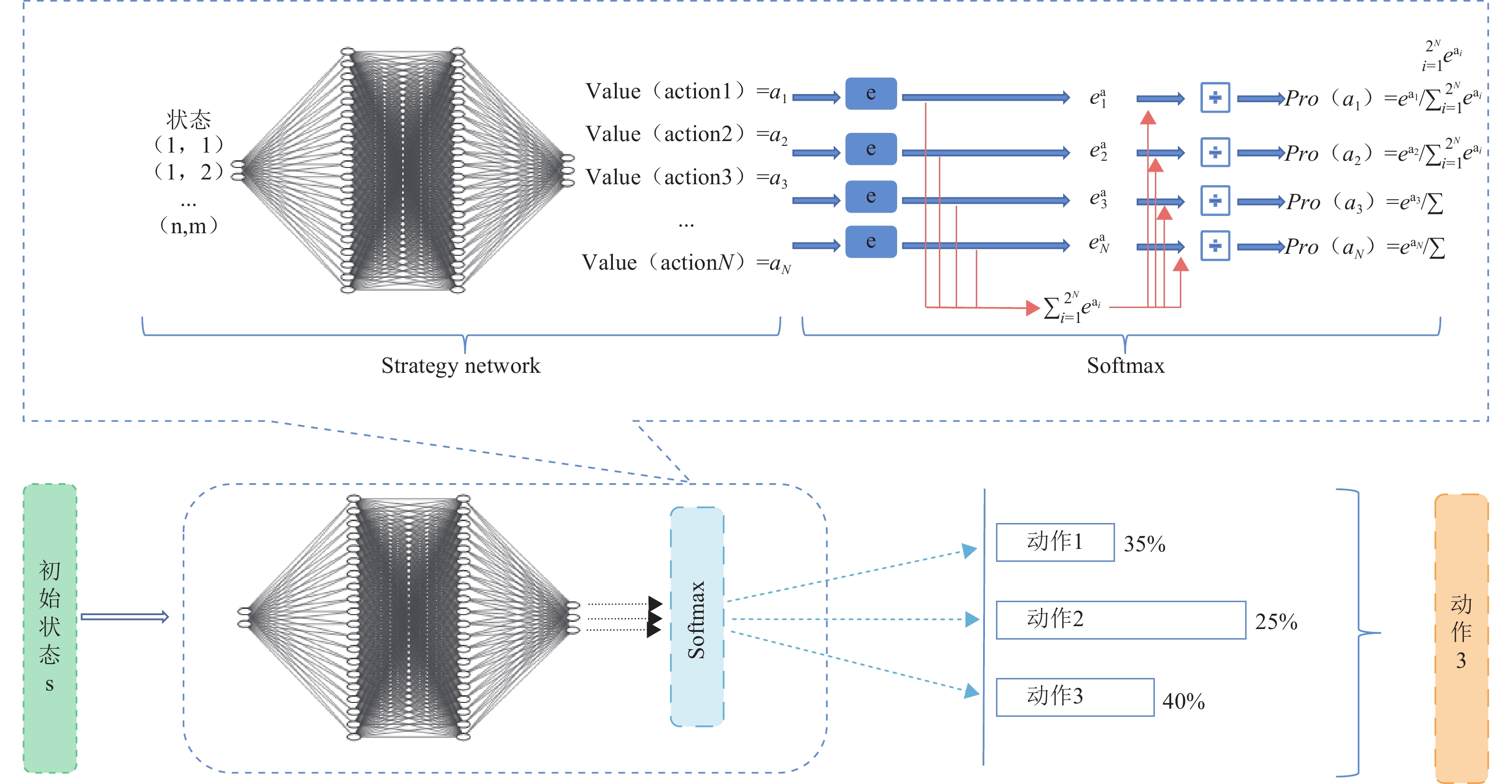
图 3基于策略梯度强化学习方法动作输出原理图
Fig. 3The principle diagram of action output based on policy gradient reinforcement learning method

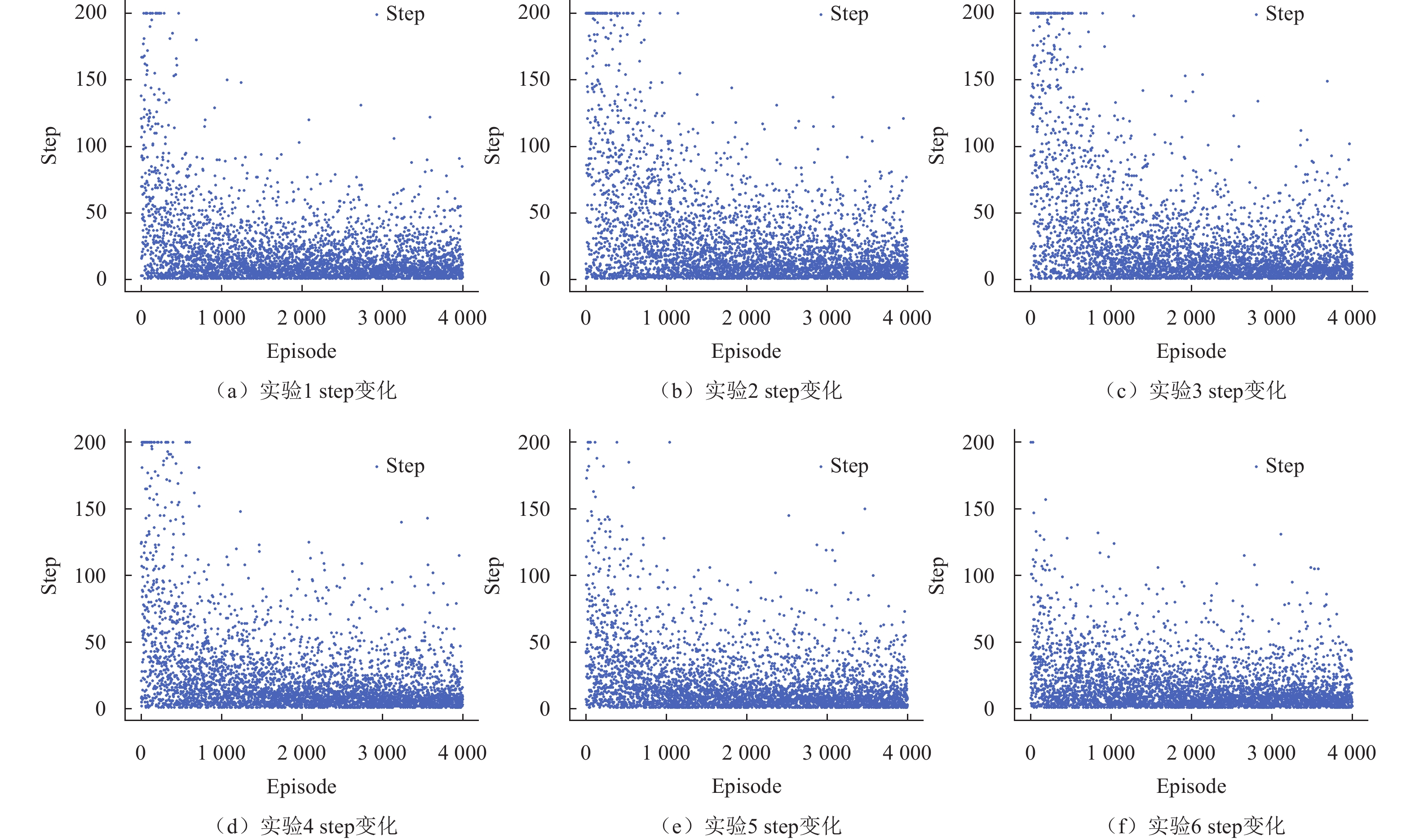
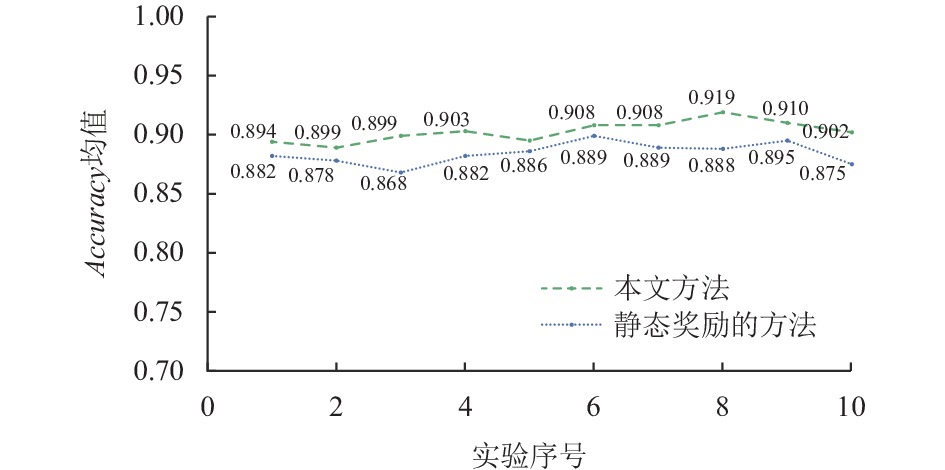
图 11动态奖励和非动态奖励Accuracy结果对比
Fig. 11Comparison of Accuracy results of dynamic reward and non-dynamic reward
表 1实验环境
Table 1Experimental environment
配置 操作系统 Windows10 64位 编程语言 Python3.8.8 cpu Intel(R) Core(TM) i5-10210U CPU @ 1.60GHz 2.11 GHz 内存 16GB 强化学习框架 PARL[24]  下载:
导出CSV
下载:
导出CSV
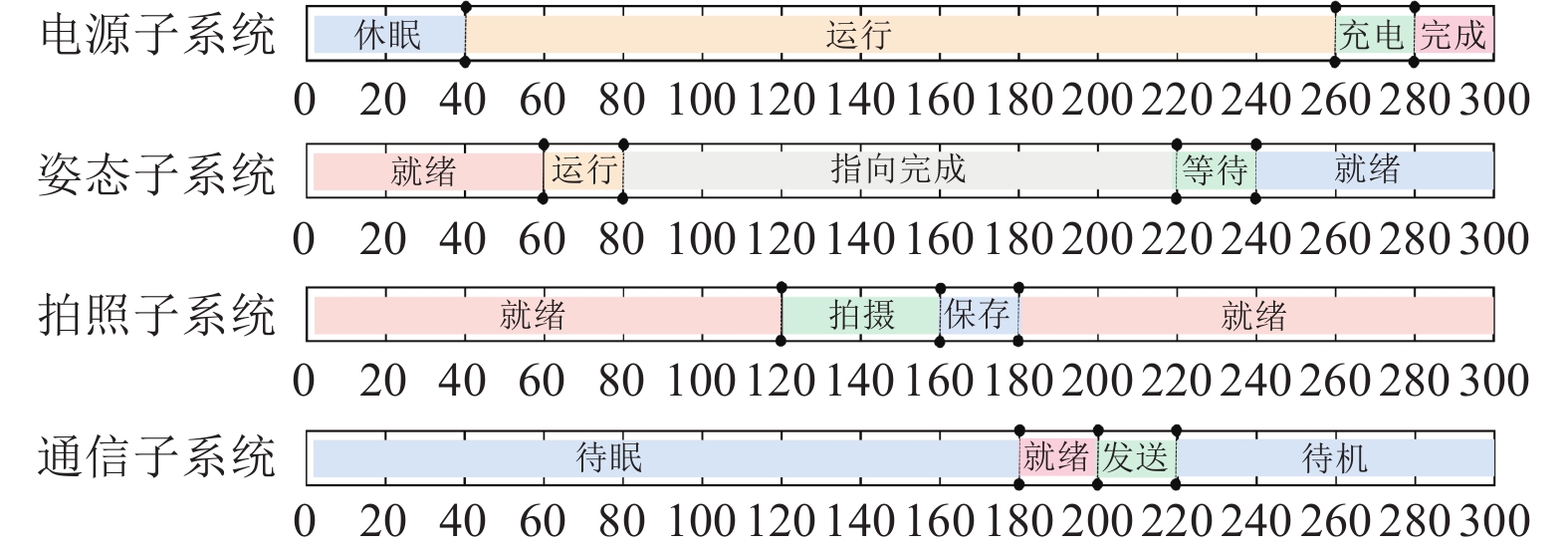
表 2所用深空探测器拍照案例
Table 2Examples of deep space probes used
子系统名称 状态 可执行动作 电源子系统 休眠 启动 运行 发送低于安全阈值信号 发送高于安全阈值信号 读取目标坐标 打开镜头 打开天线 充电 收起太阳能板 返回 姿态调整子系统 就绪 转向目标 运行 发送指向完成信号 等待 接收任务完成信号 接收任务失败信号 阻塞 接收新任务信号 指向完成 发送准备信号 拍照子系统 待机 接收姿态调整信号 关闭镜头 就绪 执行拍照 拍照 写入储存器 保存 发送失败信号 发送成功信号 通信子系统 待机 写入缓存 清空缓存并删除图像 就绪 建立连接 发送 发送连接异常信号 断开 发送传输完成信号 下载:
导出CSV
表 310次实验的Accuracy结果
Table 3Accuracy results of 10 experiments
组号 1 2 3 4 5 6 7 8 9 10 均值 实验1 0.91 0.86 0.85 0.87 0.91 0.87 0.92 0.93 0.92 0.90 0.89 实验2 0.90 0.92 0.82 0.89 0.88 0.91 0.90 0.91 0.90 0.86 0.88 实验3 0.90 0.92 0.82 0.89 0.92 0.91 0.90 0.91 0.93 0.89 0.89 实验4 0.91 0.87 0.88 0.89 0.88 0.91 0.94 0.92 0.93 0.90 0.90 实验5 0.91 0.87 0.88 0.92 0.87 0.91 0.90 0.89 0.90 0.90 0.89 实验6 0.82 0.86 0.86 0.93 0.93 0.94 0.91 0.94 0.94 0.95 0.90 实验7 0.91 0.90 0.91 0.93 0.92 0.89 0.90 0.91 0.92 0.89 0.90 实验8 0.95 0.89 0.91 0.94 0.92 0.93 0.93 0.92 0.89 0.91 0.91 实验9 0.91 0.92 0.91 0.90 0.92 0.90 0.91 0.92 0.89 0.92 0.91 实验10 0.91 0.89 0.83 0.93 0.89 0.89 0.94 0.88 0.94 0.92 0.90 下载:
导出CSV
表 410次实验的单次规划用时情况
Table 4Single planning time of 10 experiments 单位:s
组号 1 2 3 4 5 6 7 8 9 10 均值 实验1 0.109 0.111 0.122 0.121 0.117 0.113 0.112 0.132 0.110 0.114 0.116 1 实验2 0.116 0.112 0.115 0.110 0.107 0.112 0.109 0.108 0.107 0.112 0.110 8 实验3 0.112 0.111 0.111 0.112 0.110 0.111 0.109 0.113 0.109 0.113 0.111 1 实验4 0.110 0.112 0.113 0.113 0.113 0.106 0.107 0.106 0.111 0.111 0.110 2 实验5 0.112 0.113 0.114 0.116 0.116 0.119 0.114 0.121 0.116 0.12 0.116 1 实验6 0.116 0.111 0.113 0.110 0.112 0.107 0.110 0.108 0.112 0.112 0.111 1 实验7 0.113 0.113 0.112 0.111 0.113 0.110 0.114 0.108 0.112 0.113 0.111 9 实验8 0.110 0.109 0.111 0.114 0.110 0.110 0.112 0.110 0.106 0.110 0.110 2 实验9 0.109 0.107 0.111 0.110 0.112 0.112 0.109 0.109 0.112 0.110 0.110 1 实验10 0.112 0.111 0.111 0.111 0.110 0.112 0.115 0.112 0.112 0.112 0.111 8 下载:
导出CSV
-
[1] 崔平远. 深空探测:空间拓展的战略制高点[J]. 人民论坛·学术前沿,2017(5):13-18.doi:10.16619/j.cnki.rmltxsqy.2017.05.002CUI P Y. Deep space exploration:strategic height of space expansion[J]. People's Forum. Academic Frontier,2017(5):13-18.doi:10.16619/j.cnki.rmltxsqy.2017.05.002 [2] 于登云,张兴旺,张明,等. 小天体采样探测技术发展现状及展望[J]. 航天器工程,2020,29(2):1-10.doi:10.3969/j.issn.1673-8748.2020.02.001YU D Y,ZHANG X W,ZHANG M,etc. Current status and prospects of small object sampling and detection technology[J]. Spacecraft Engineering,2020,29(2):1-10.doi:10.3969/j.issn.1673-8748.2020.02.001 [3] 赵凡宇,徐瑞,崔平远. 启发式深空探测器任务规划方法[J]. 宇航学报,2015,36(5):496-503.ZHAO F Y,XU R,CUI P Y. Heuristic mission planning method for deep space probes[J]. Journal of Astronautics,2015,36(5):496-503. [4] 姜啸,徐瑞,朱圣英. 基于约束可满足的深空探测任务规划方法研究[J]. 深空探测学报(中英文),2018,5(3):262-268.JIANG X,XU R,ZHU S Y. Research on constrained satisfiable deep space mission planning method[J]. Journal of Deep Space Exploration,2018,5(3):262-268. [5] 姜啸,徐瑞,陈俐均. 深空探测器动态约束规划中的外延约束过滤方法研究[J]. 深空探测学报(中英文),2019,6(6):586-594.JIANG X,XU R,CHEN L J. Study on extensive constraint filtering method for dynamic constraint planning of deep space detector[J]. Journal of Deep Space Exploration,2019,6(6):586-594. [6] 金颢,徐瑞,朱圣英,等. 适用于深空探测器的时间线转移路标启发式规划方法[J]. 宇航学报,2021,42(7):862-872.doi:10.3873/j.issn.1000-1328.2021.07.006JIN B,XU R,ZHU S Y,etc. Time line transfer landmark heuristic planning method for deep space detector[J]. Journal of Astronautics,2021,42(7):862-872.doi:10.3873/j.issn.1000-1328.2021.07.006 [7] 赵宇庭,徐瑞,李朝玉,等. 基于动态智能体交互图的深空探测器任务规划方法[J]. 深空探测学报(中英文),2021,8(5):519-527.ZHAO Y T,XU R,LI C Y,etc. Mission planning method for deep space probe based on dynamic agent interaction diagram[J]. Journal of Deep Space Exploration (English),2021,8(5):519-527. [8] 王晓晖,李爽. 深空探测器约束简化与任务规划方法研究[J]. 宇航学报,2016,37(7):768-774.WANG X H,LI S. Research on Constraint Simplification and Task Planning Method for Deep Space Detector[J]. Journal of Astronautics,2016,37(7):768-774. [9] 冯小恩,李玉庆,杨晨,等. 面向自主运行的深空探测航天器体系结构设计及自主任务规划方法[J]. 控制理论与应 用,2019,36(12):2035-2041.FENG X E,LI Y Q,YANG C,etc. Architecture design and autonomous mission planning for autonomous deep space exploration spacecraft[J]. Control Theory and Application,2019,36(12):2035-2041. [10] 王鑫,赵清杰,徐瑞. 基于知识图谱的深空探测器任务规划建模[J]. 深空探测学报(中英文),2021,8(3):315-323.WANG X,ZHAO Q J,XU R. Modeling of deep space probe mission planning based on knowledge map[J]. Journal of Deep Space Exploration (English),2021,8(3):315-323. [11] 李玉庆,徐敏强,王日新. 航天器观测重调度问题中的模糊性不确定因素及其处理[J]. 宇航学报,2009,30(3):1106-1111.doi:10.3873/j.issn.1000-1328.2009.03.045Li Y Q,XU M Q,WANG R X. Fuzzy Uncertainty Factors in Spacecraft Observation Rescheduling Problem and Their Processing[J]. Journal of Astronautics,2009,30(3):1106-1111.doi:10.3873/j.issn.1000-1328.2009.03.045 [12] 贺东雷,冯小恩,雷明佳,等. 面向深空探测任务的实数遗传编码多星任务规划算法[J]. 控制理论与应用,2019,36(12):2055-2064.HE D L,FENG X E,LEI M J,etc. Real-number genetic encoding multistar mission planning algorithm for deep space mission[J]. Control Theory and Application,2019,36(12):2055-2064. [13] SUTTON R, BARTO A. Reinforcement Learning: An Introduction[M]. MIT Press, 1998. [14] 史兼郡,张进,罗亚中,等. 基于深度强化学习算法的空间站任务重规划方法[J]. 载人航天,2020,26(4):469-476.doi:10.3969/j.issn.1674-5825.2020.04.008SHIJ J,ZHANG J,LUO Y Z,etc. Space station task replanning method based on deep enhanced learning algorithm[J]. Manned Space,2020,26(4):469-476.doi:10.3969/j.issn.1674-5825.2020.04.008 [15] 伍国威, 崔本杰, 曲耀斌, 等. 基于深度强化学习的卫星实时引导任务规划方法及系统: CN111950873A[P]. 2020.WU G W, CUI B J, QU Y B, et al. Satellite real-time guidance mission planning method and system based on deep reinforcement learning: CN111950873A[P]. 2020. [16] 郭林杰. 基于深度强化学习的跳跃式小行星探测器规划策略研究[D]. 哈尔滨: 哈尔滨工业大学, 2019.GUO L J. Study on planning strategy of skip asteroid detector based on deep reinforcement learning [D]. Harbin: Harbin University of Technology, 2019. [17] FURFARO R, LINARES R. Deep learning for autonomous lunar landing[C]// AAS/AIAA Astrodynamics Specialist Conference. [S. l.]: AIAA, 2018. [18] HECKE K V, DE CROON G C H E, HENNES D, et al. Self-supervised learning as an enabling technology for future space exploration robots: ISS experiments on monocular distance learning[J]. Acta Astronautica, 2017: S0094576517302862. [19] 徐瑞,李朝玉,朱圣英,等. 深空探测器自主规划技术研究进展[J]. 深空探测学报(中英文),2021,8(2):111-123.XU R,LI C Y,ZHU S Y,etc. Progress in Deep Space Explorer Autonomous Planning[J]. Journal of Deep Space Exploration (English),2021,8(2):111-123. [20] 刘志荣,姜树海. 基于强化学习的移动机器人路径规划研究综述[J]. 制造业自动化,2019,41(3):90-92.LIU Z R,JIANG S H. A review of path planning for mobile robots based on reinforcement learning[J]. Manufacturing Automation,2019,41(3):90-92. [21] 俞胜平, 韩忻辰, 袁志明, 崔东亮. 基于策略梯度强化学习的高铁列车动态调度方法[J]. 控制与决策,YU S P, HAN X C, YUAN Z M, CUI D L. Dynamic scheduling method of high-speed train based on policy gradient reinforcement learning [J]. Control and Decision. [22] 张淼,张琦,刘文韬,等. 一种基于策略梯度强化学习的列车智能控制方法[J]. 铁道学报,2020,42(1):69-75.doi:10.3969/j.issn.1001-8360.2020.01.010ZHANG B,ZHANG Q,LIU W T,etc. A train intelligent control method based on strategic gradient enhanced learning[J]. Journal of Railways,2020,42(1):69-75.doi:10.3969/j.issn.1001-8360.2020.01.010 [23] 周飞燕,金林鹏,董军. 卷积神经网络研究综述[J]. 计算机学报,2017,40(6):1229-1251.doi:10.11897/SP.J.1016.2017.01229ZHOU F Y,JIN L P,Dong Jun. A review of convolution neural networks[J]. Journal of Computer Science,2017,40(6):1229-1251.doi:10.11897/SP.J.1016.2017.01229 [24] 李高杨,吕晓鹏,张星. 基于强化学习的交通信号控制及深度学习应用[J]. 人工智能,2020(3):84-9.Li G Y,LV X P,ZHANG X. Application of traffic signal control and in-depth learning based on reinforcement learning[J]. Artificial Intelligence,2020(3):84-9. -
 下载:
下载:






计量
- 文章访问数:91
- 被引次数:0
